Personal tools
Document Actions
PGHPF Compiler User's Guide - 6 Runtime and Execution Model
 << " border=0>
<< " border=0>
 > " border=0>
> " border=0>





6 Runtime and Execution Model
Performance for HPF programs and their communications on any particular parallel system is influenced by several factors including i) the amount of communications required by a program, ii) the amount of computation and I/O, and iii) the system's latency and bandwidth when communication is required. Another factor that influences performance is the number and power of optimizations performed to improve or eliminate communications. Latency describes the minimum time required for communication between two processors. Bandwidth refers to the maximum rate at which a message can be sent from one processor to another. Optimizations group communications to eliminate unnecessary communications, minimize the effects of latency and to maximize bandwidth per communication. Some communication optimizations that PGHPF performs are covered in this chapter while other factors such as system configuration, latency and bandwidth are useful to keep in mind while considering a program's performance on a parallel system.
6.1 Communication Optimization
Communication is divided into a hierarchy of types with the lowest types in the hierarchy being most expensive. The hierarchy is as follows (number one below is the least expensive, number six is the most expensive):
- No communication. The left and right hand side arrays reside on the same processor.
- Overlap shift. A BLOCK-distributed array is involved in a shift communication pattern. The local array section is enlarged by the shift amount, and the boundary elements are transferred from neighboring processors.
- Copy section. An array section with arbitrary distribution is assigned to another array section with arbitrary distribution.
- Gather/Scatter. An array is indexed with an arbitrary subscript, but the evaluation of the subscript does not involve any communication. For example, this primitive can efficiently handle the transpose or diagonal accesses that may arise in a FORALL statement.
- Gather/Scatter handles the case when an array is indexed with a subscript that involves communication.
- Scalarization. No efficient communication pattern was found, so every processor performs the entire loop, broadcasting the data that it owns one element at a time, and storing the results that it owns.
Table 6-1 shows the hierarchy of communication patterns based on the owner computes rule, showing the form of the left-hand-side and right-hand-side. The table indicates special cases that are optimized for efficient communications.
Table 6-1: Communication Primitives - General Case
Left Hand Side |
Right Hand Side |
Communication Primitive Name |
i |
i |
No communication required |
i |
i+c |
Overlap Shift (optimized) |
i |
s*i+c |
Copy Section (optimized) |
i |
j |
Unstructured (permute section) |
i |
v(i) |
Gather/Scatter |
v(i) |
i |
Gather/Scatter |
i |
unknown |
Scalarization (scalar communications) |
unknown |
i |
Scalarization (scalar communications) |
c: compile time constant
s: scalar
i, j: FORALL index variables
6.1.1 Replicated Data
When data is replicated a computation has no parallelism and communication is minimized. The following program replicates the A and B arrays across all processors. No communication is required for the computation. This follows the first pattern shown in Table 6-1.
PROGRAM TEST45
INTEGER I, A(100), B(100)
!HPF$ DISTRIBUTE (*):: A,B
B=A
END
6.1.2 Overlap Shift Communications
The overlap shift communications optimization recognizes computations with arrays that contain an overlap pattern as shown in table 6-1. When the array involved in an overlap shift computation is allocated the overlap area is also allocated and remains available until a computation requiring the overlap area. Immediately before the computation, the overlap area is filled with the current value(s) of the overlap data (this requires communication). By allocating an overlap shift area, the compiler localizes a portion of a computation prior to the computation that would otherwise require communication during computation. Figure 6-2 graphically shows the overlap shift optimization for code similar to the following.
PROGRAM TEST_OVERLAP
INTEGER I, A(8), B(8)
!HPF$ DISTRIBUTE (BLOCK):: A,B
FORALL(I=1:7) A(I)=B(I+1)
END
In the first stage of the overlap shift communication, the compiler determines that a computation involving the array B requires an overlap shift area in the positive direction (PGHPF also permits negative overlap shift areas). A portion of B is then allocated with the extra overlap location(s).
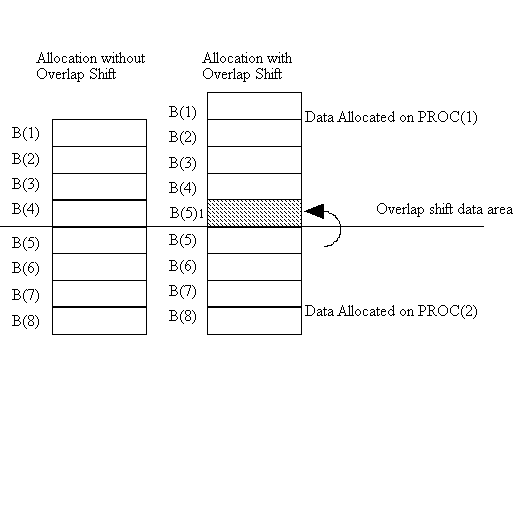
Figure 6-2 Sample Overlap Shift Optimization
Overlap Shift Optimization
A compilation flag is available to control the size of the overlap area the compiler generates for certain array expressions. The overlap area is only generated and used for BLOCK distributed arrays. For most programs, the compiler's default handling for overlap areas should suffice as a balance between memory needs and the possible use of the overlap shift communications optimization. However, in some cases using too large an overlap area may result in a runtime memory allocation error such as the following:
0: ALLOCATE: xxxx bytes requested; not enough memory
The overlap option is available for such cases. Use -Moverlap as follows:
%pghpf -Moverlap=size:n
This option controls the size of the overlap area the compiler generates for certain arrays. In some cases, increasing or decreasing the size of the overlap area may improve a program's performance. The default size is 4. You may want to change the size from the default to improve performance in cases where PGHPF generates overlap_shift() communications. For example in the code:
!hpf$ distribute (block) :: a,b
forall(i=1:n) a(i) = b(i+10)
using the default overlap size of 4, PGHPF does not use the overlap shift optimization, since 4 is too small. By increasing the overlap size to 10, PGHPF generates overlap shifts.
The compiler only performs overlap shift communications for BLOCK distributed dimensions where an array's shift amount is a compile time constant and is less than the overlap default, or the size specified with -Moverlap.
Reducing the overlap size may improve performance for some codes. Setting the size to 0 disables overlap shifts. If a program's expressions utilizing the overlap area never use an offset greater than two, then specifying an overlap size smaller than the default, for example a value of 2, will reduce memory usage and may reduce communications. For example, the following code shows an expression that would only require on overlap size of 1.
!hpf$ distribute (block) :: a,b
forall(i=1:n) a(i) = b(i-1) + b(i) + b(i+1)
6.1.3 Copy Section Communications
The copy section communications optimization recognizes computations with arrays that contain an expression as one of the array index values on the right-hand-side. This optimization recognizes an expression with a scalar, an index value, and a constant. With the copy section optimization, the compiler allocates a temporary array to hold the array section. This temporary is filled with the current values of the array immediately before the computation. The computation then involves temporary arrays which are already localized. This optimization allows a group of values to be localized and communicated prior to the computation.
Following is a sample of code that would use the copy section communications optimization.
PROGRAM TEST_SECTION
INTEGER SCALAR_VAL, I, A(100), B(100)
!HPF$ DISTRIBUTE (BLOCK)::A,B
READ *, SCALAR_VAL
FORALL(I=1:100) A(I)=B(SCALAR_VAL*I+1)
END
6.1.4 Indirection References and Scheduling
The compiler creates schedules for communications. Schedules are part of the overhead involved with communications. One optimization that PGHPF performs, using level -O2, involves reusing schedules for communications within loops; this reduces the required communications overhead.
Indirection arrays generally require expensive scheduling. By careful programming, one can reduce the number of schedules generated. For example, consider the following code segment:
!hpf$ distribute (block, block) :: FR, FI do i = 1, n
FR(i,:) = FR(i, v(:))
enddo do i = 1, n
FI(i,:) = FI(i, v(:))
enddo
The compiler generates two schedules for the code above, because schedules are not reused across loops. However, if the code is written as follows, the compiler will reuse the first communications schedule for the second array assignment:
do i = 1, n
FR(i,:) = FR(i, v(:))
FI(i,:) = FI(i, v(:))
enddo
The compiler generates two communication schedules for FR(i,v(:)) and FI(i,v(:)). If the code is written as in the second example, PGHPF generates one schedule and reuses this schedule for the second communication.
Since the value of v is not changed between statements and its second use is in the loop, PGHPF may be able to use a single schedule for the different communications, thus reducing the overhead required for producing the communications schedule.
Another technique that allows the compiler to optimize this type of communication is indirection array alignment. When an indirection array is found on the right-hand-side of an expression, it is better to align with the left-hand-side, or to replicate the indirection array.
Similarly, if you use indirection for the left-hand-side, it is better to align the indirection with one of the right-hand-side arrays.
The compiler also recognizes patterns within FORALL statements and constructs as scatter operations. For example, in the statement:
A(V) = A(V) + B
generates a call to an internal SUM_SCATTER operation which is similar to the SUM_SCATTER routine found in the HPF library.
Another optimization that a programmer may use involves generating indirection arrays to reduce the use of expensive scalar communications. Using the compiler option -Minfo, the compiler provides diagnostic messages when the compiler scalarizes a FORALL. For example:
4, forall is scalarized: complicated communication
If a FORALL construct uses an array index with complicated subscripts, it may be better to put complicated array subscripts into an indirection array. For example the following two code segments show how this is accomplished:
forall(i=1:n) FR(I) = FR(I/2+2*v(i))
this code could be replaced to use an indirection array, as shown:
forall(i=1:N) indx(i) = i/2+2*v(i) forall(i=1:N) fr(i) = fr(indx(i))
Here the PGHPF will not scalarize the complicated subscripts in the FORALL statements in the second example, since the index is a simple indirection, and does not add the extra complication of a complicated computation and an indirection.
6.2 Program Performance Measurement
If you are comparing an HPF program to check its performance using several different algorithms, there are several relevant parameters to use when measuring performance.
Parallel speedup measures the decrease in program execution time as more
processors are added. If
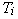 is the time to execute the program with i processors, then
perfect speedup occurs when
is the time to execute the program with i processors, then
perfect speedup occurs when
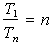 .
.
Another measure of speedup that may be used is the comparison of a program's parallel execution time with the execution time of an optimized sequential version of the program.
Another way to measure the efficiency of compiler-generated code for a parallel program is to compare it against a hand-optimized, parallel version of the same program.
The system_clock() intrinsic allows you to time a program in a portable manner:
integer :: nprocs, hz, clock0, clock1
real :: time
integer, allocatable :: t(:)
!
!hpf$ distribute t(cyclic)
!
#if defined (HPF)
allocate (t(number_of_processors())
#else
allocate (t(1))
#endif
call system_clock(count_rate = hz)
!
call system_clock(count = clock0)
C ... do work
C that needs timing. ...
call system_clock(count = clock1)
!
t = (clock1 - clock0)
time = real (sum(t)) / (real(hz) * size(t))
<< " border=0>
> " border=0>